11 多层感知机
11.1 感知机
11.1.1 定义
Def 11.1 (感知机)
- Let
- \(\mathbf {x}\) 输入
- \(\mathbf {w}\) 权重
- \(b\) 偏移量
- \(o\) 输出 (Outputs)
- Then, we call \[o=\sigma\left(\langle \mathbf {w}, \mathbf {x} \rangle + b\right) \quad\text{with}\quad \sigma(x)=\left\{\begin{align}1&\quad\text{if } x>0 \\ 0& \quad\text{otherwise} \end{align}\right.\]
- 感知机
- 感知机实际上就是神经网络中的一个神经单元.
- 感知机能解决二分类问题, 但与线性回归和softmax回归有所区别: 线性回归与softmax回归的输出均为实数, softmax回归的输出同时还满足概率公理.
11.1.2 训练
initialize w = 0 and b = 0
repeat
#此处表达式小于0代表预测结果错误
if y_i[<w,x_i>+b] <= 0 then
w=w + yixi
b=b + yi
end if
until all classified correctly可以看出这等价于使用如下损失函数的随机梯度下降 (batch_size=1) : \[ \ell(y,\mathbf{x},\mathbf {w})=max(0,-y\langle \mathbf {w},\mathbf {x}\rangle)\ = \max(0,-y\mathbf {w}^T\mathbf {x}) \] 当预测错误时, 偏导数为 \[ \frac{\partial \ell}{\partial \mathbf {w}}=-y\cdot \mathbf {x} \]
11.1.3 收敛定理
设数据在特征空间能被半径为r的圆 (球) 覆盖, 并且分类时有余量 (即\(\sigma\)函数的输入不会取使输出模棱两可的值) \(y(\mathbf {x}^T\mathbf {w})\geq \rho\), 若初始参数满足\(|\mathbf {w}|^2+b^2 \leq 1\), 则感知机保证在\(\dfrac{r^2+1}{\rho ^2}\)步内收敛
11.1.4 缺陷
然而, 这种线性划分依赖于线性假设, 是非常不可靠的
- 线性假设意味着单调假设, 这是不可靠的:
- 对于人体的体温与健康情况的建模, 人体在37℃时最为健康, 过小过大均有风险, 然而这不是单调的
- 线性假设意味着特征与预测存在线性相关性, 这也是不可靠的:
- 如果预测一个人偿还债务的可能性, 那这个人的资产从0万元增至5万元和从100万元增至105万元对应的偿还债务的可能性的增幅肯定是不相等的, 也就是不线性相关的
- 线性模型的评估标准是有位置依赖性的, 这是不可靠的:
- 如果需要判断图片中的动物是猫还是狗, 对于图片中一个像素的权重的改变永远是不可靠的, 因为如果将图片翻转, 它的类别不会改变, 但是线性模型不具备这种性质, 像素的权重将会失效
课程中所提到的例子是XOR问题, 即希望模型能预测出XOR分类.
解决方案
多层感知机 (下面介绍)
11.2 多层感知机
我们可以通过在网络中加入一个或多个隐藏层来克服线性模型的限制, 使其能处理更普遍的函数关系类型. 要做到这一点, 最简单的方法是将许多全连接层堆叠在一起. 每一层都输出到上面的层, 直到生成最后的输出.
11.2.1 单隐藏层

这里的模型称为多层感知机, 第一层圆圈 \(x_1,x_2,x_3,x_4\) 称为输入 (实际上他并非感知机) , 之后的一层称为隐藏层, 由5个感知机构成, 他们均以前一层的信息作为输入, 最后是输出层, 以前一层隐藏层的结果作为输入. 除了输入的信息和最后一层的感知机以外, 其余的层均称为隐藏层, 隐藏层的设置为模型一个重要的超参数, 这里的模型有一个隐藏层.
11.2.2 激活函数 (Activation function)
但是仅仅有线性变换是不够的, 如果我们简单的将多个线性变换按层次叠加, 由于线性变换的结果仍为线性变换, 所以最终的结果等价于线性变换, 与单个感知机并无区别, 反而加大了模型, 浪费了资源, 为了防止这个问题, 需要对每个单元 (感知机) 的输出通过激活函数进行处理再交由下一层的感知机进行运算, 这些激活函数就是解决非线性问题的关键.
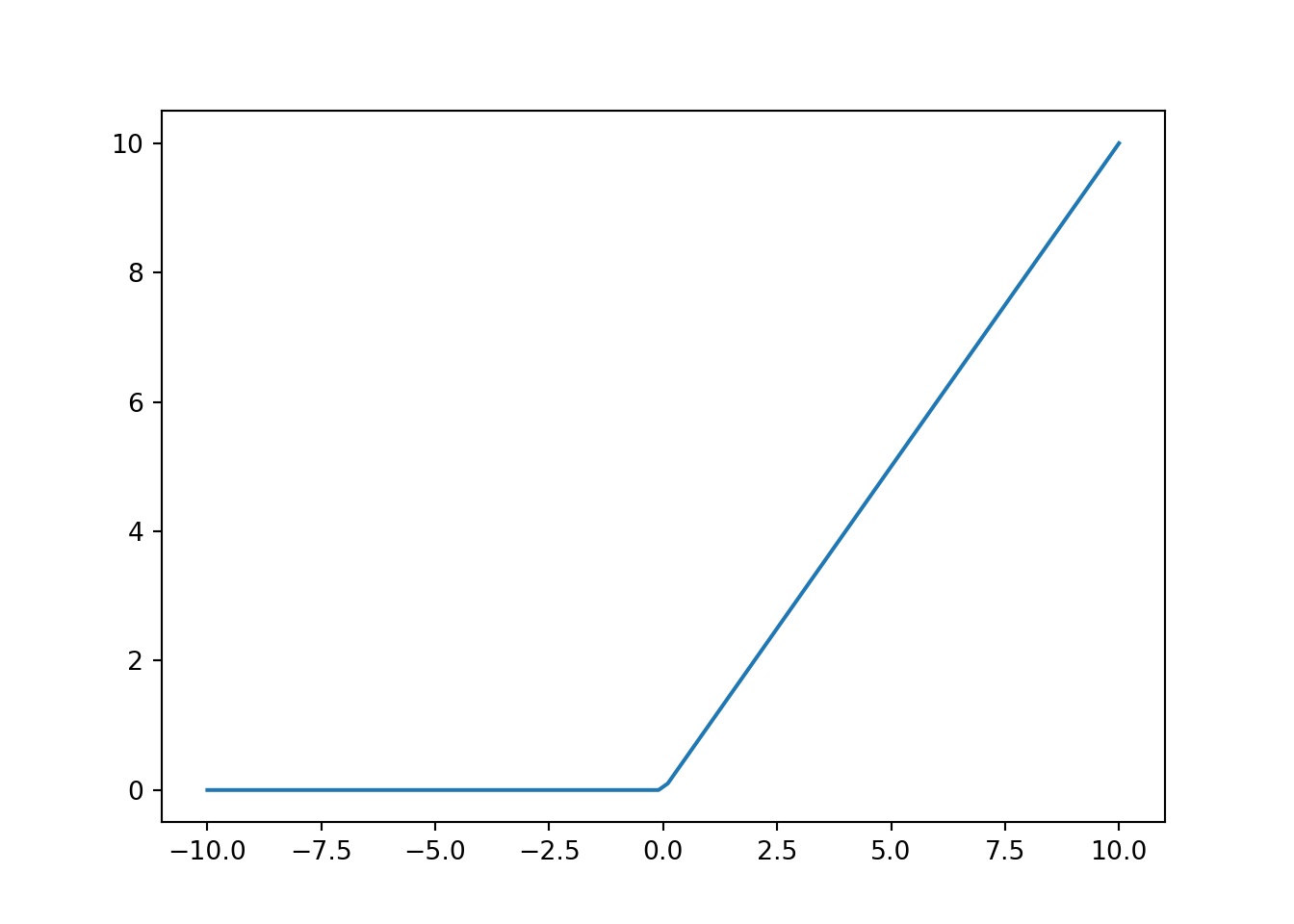
11.2.2.1 ReLU函数
最受欢迎的激活函数是修正线性单元 (Rectified linear unit, ReLU) , 因为它实现简单, 同时在各种预测任务中表现良好. ReLU提供了一种非常简单的非线性变换. 给定元素\(x\), ReLU函数被定义为该元素与\(0\)的最大值: \[ \operatorname{ReLU}(x) = \max(x, 0) \] ReLU函数通过将相应的活性值设为0, 仅保留正元素并丢弃所有负元素. 为了直观感受一下, 我们可以画出函数的曲线图. 正如从图中所看到, 激活函数是分段线性的. 使用ReLU的原因是, 它求导表现得特别好: 要么让参数消失, 要么让参数通过. 这使得优化表现的更好, 并且ReLU减轻了困扰以往神经网络的梯度消失问题
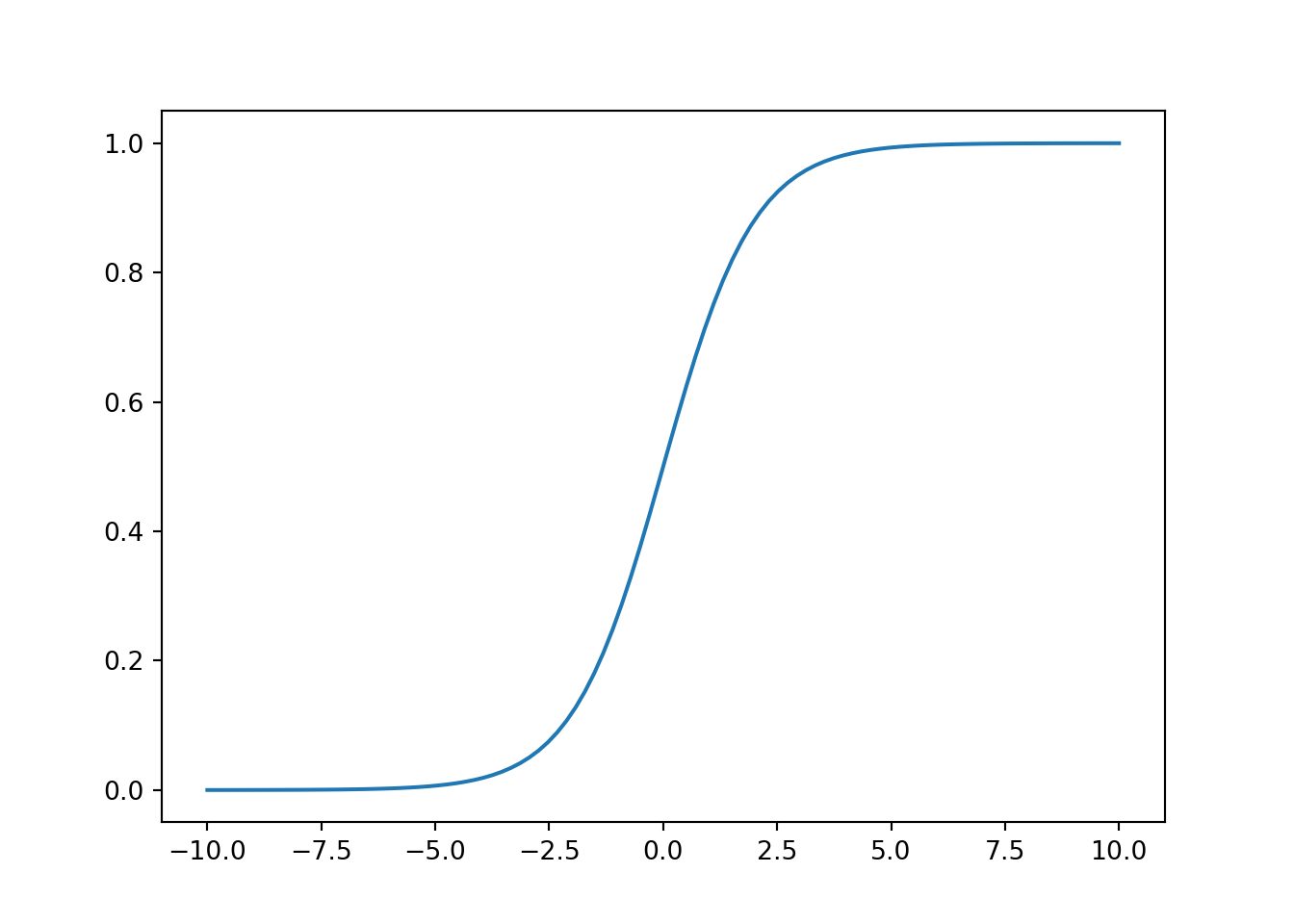
11.2.2.2 sigmoid函数
对于一个定义域在\(\mathbb{R}\)中的输入, sigmoid函数将输入变换为区间(0,1)上的输出. 因此, sigmoid通常称为挤压函数 (squashing function) : 它将范围 \((-\infty, \infty)\) 中的任意输入压缩到区间 (0,1) 中的某个值: \[ \operatorname{sigmoid}(x) = \frac{1}{1 + e^{-x}}. \]
在基于梯度的学习中, sigmoid函数是一个自然的选择, 因为它是一个平滑的、可微的阈值单元近似. 当我们想要将输出视作二元分类问题的概率时, sigmoid仍然被广泛用作输出单元上的激活函数 (你可以将sigmoid视为softmax的特例). 然而, sigmoid在隐藏层中已经较少使用, 它在大部分时候被更简单、更容易训练的ReLU所取代.
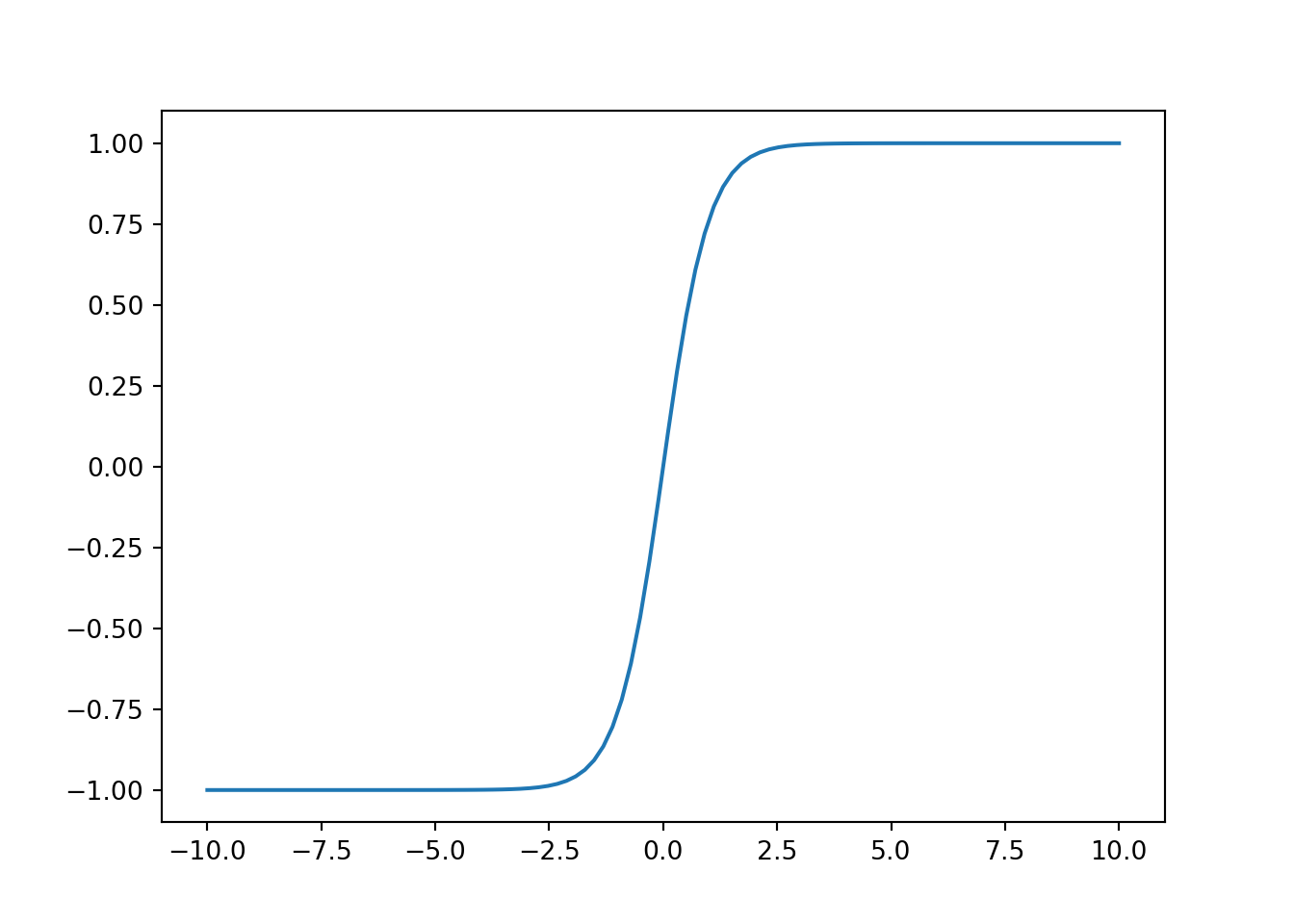
11.2.2.3 tanh函数
与sigmoid函数类似, tanh(双曲正切)函数也能将其输入压缩转换到区间(-1,1)上. tanh函数的公式如下: \[ \operatorname{tanh}(x) = \frac{1 - e^{-2x}}{1 + e^{-2x}} \]
11.2.3 总结
- 多层感知机使用隐藏层和激活函数来得到非线性模型
- 常用激活函数:Sigmoid,Tanh,ReLU
- 使用softmax进行多分类
- 隐藏层数、大小为超参数